written by owen on 2019-Mar-16.
When I started on the 1.4 update I quickly realised that the index could not be updated in one go anymore since I had increased the crawl depth to 4 levels deep. this would be a problem since if the crawl does not finish then there would be no index on which the search engine would run. I needed another cache. Now enters the path cache. As I crawl from link to link I need to keep track of how far I am into the rabbithole and where I have already been. before all I had to do was make sure I was not wasting time re-downloading html but now even the cached html is too much for my little old machine. Here are the results of the new cache;
path_cache is 199 mb, 5355 files
build_cache is 209 mb, 30,012 files
html_cache is 1.81gb, 50,411 files
html_cache is loaded from reading the website raw html.
build_cache is created from reading the html cache and gathering some meta information which will later be used to build the search index.
This new path_cache allows me to crawl deeper into websites while still being able to continue if I time out/crash. Originally I could go 3 links deep with only the build_cache and the html_cache but now that I have added a 4th level I can no longer move through all the cache files quick enough to build a search index. So the path_cache is sorta like leaving a train of bread crumbs to grandma's house. Hopefully when I am finished with the trail I can build a new search index.
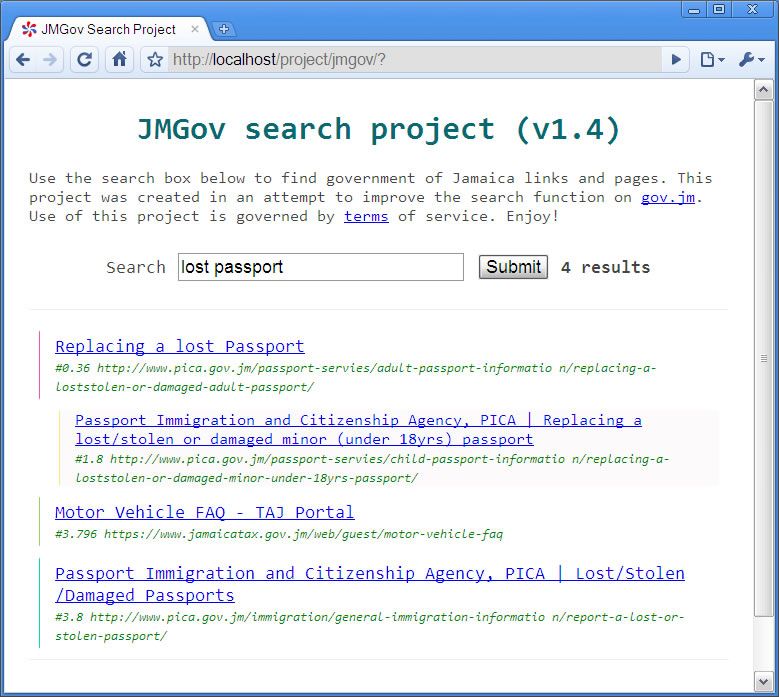
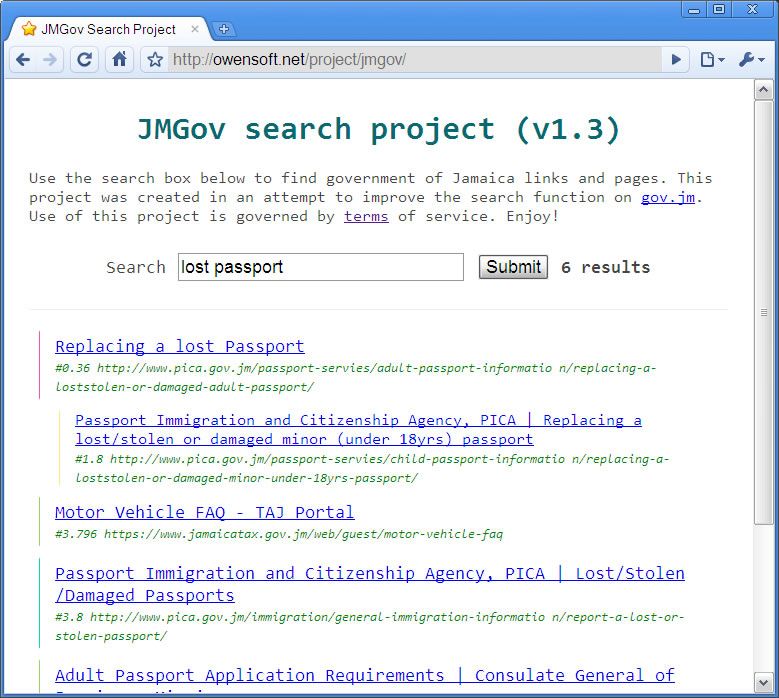
So the index finally updated and the result is a quarter the size of the previous index (4.2 KB) which means that I am probably missing a tonne of links or my index has become super efficient. I tend to lean towards the later since I am coming down from a 15.7mb index. I know that it should not be possible to have duplicate links so I must be missing a bunch. I will have to test it to see or build a comparison script.
I eventually fixed it. It turned out the levels that I had implemented in the new path_cache system were not deep enough to actually leave the root website. I have to be constantly checking to make sure I am not crawling in circles. The list cache is now bigger 18.9KB (most likely because of dumb the link structure of visitjamaica). Searching takes like 5 seconds on my personal computer.
I also added a new list of crawled links totalling 5474 links (331kb).
The next task will be finding a way to divide up the search db into smaller chunks for faster searching. Of course dividing will result in many more files and duplicate information everywhere but that is the sacrifice that will have to be made inorder to speed up the search.
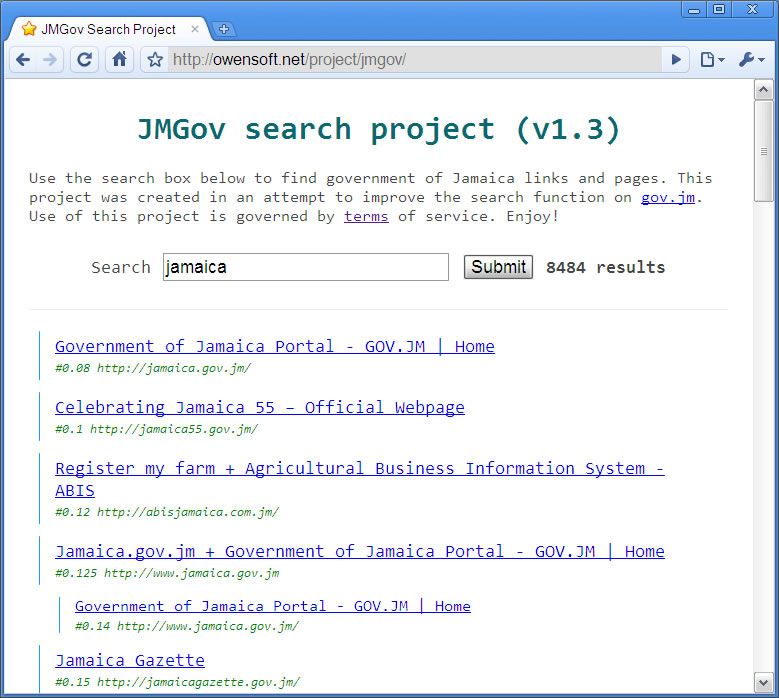
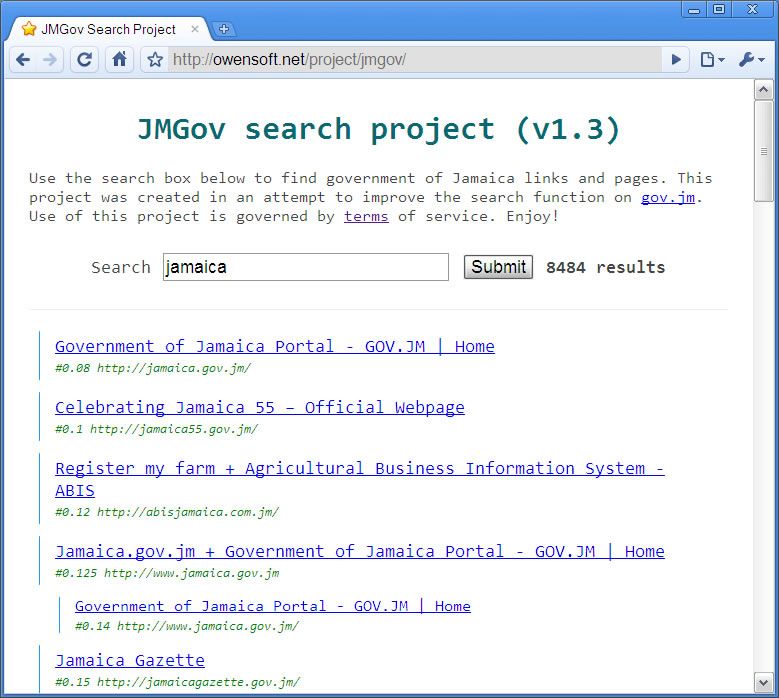
Current Stats
Links: 24437
Words: 25026
permanent link. Find similar posts in ChangeLog.
comments
Comment list is empty. You should totally be the first to Post a comment or feature request.