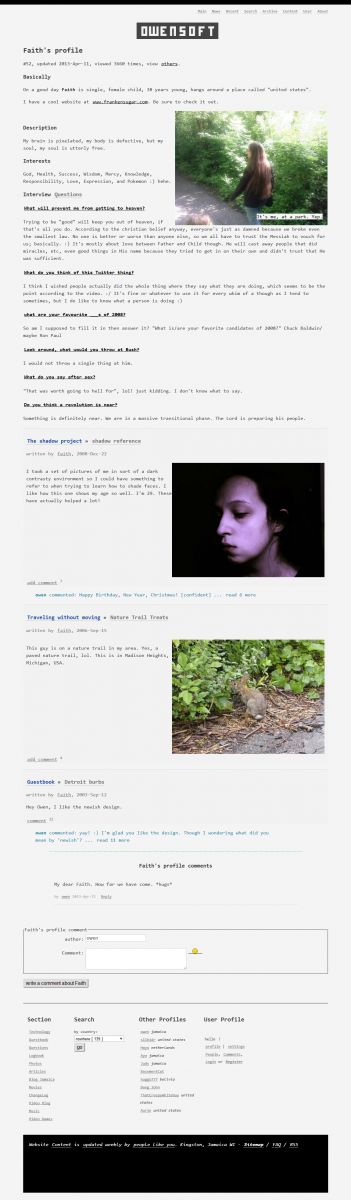
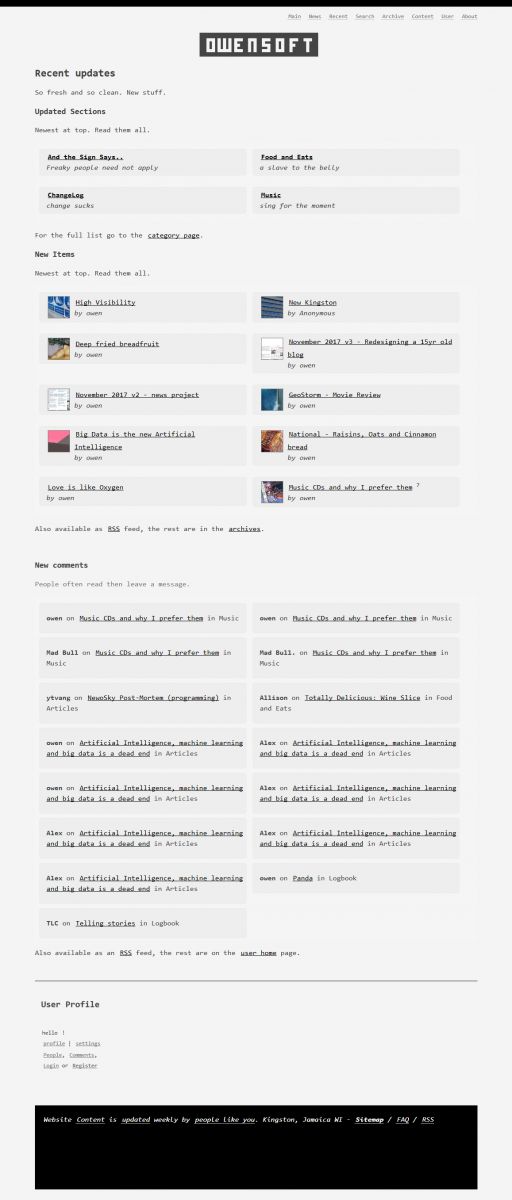
The year is running by so fast I cannot believe it is March already. Time for the yearly design refresh. I fixed some issues I had with how the website displays on the PS4.
I made a custom colour picker because I got tired of colour web services and wanted something simple.
I have made some an updates to Newofox including the ability to do barrel rolls and other bug fixes.
Created new project called "Code" where I can upload little snippets of programming code that I feel would be useful to other programmers. I dont really have a theme for that section yet but I figured I would through it up because I procrastinated on starting it for too long. The first upload is an achievement system that created in C for one of my old games. It is hard to find stuff like that on the internet nowadays because most code is now written in monolithic OOP. Or worst yet on APIs on mobile phones have transformed those systems into services (SaaS). So if you ask anyone how to do it in code they either dont know or they come up with some kinda convoluted object inheritance map. My approach is much more dynamic by maintaining a relational array of numbers that update each other when certain events happen. Only 2 events are really needed "addition" and "reset". Anyway I am not going to bore you all with the details.
I also need to put in some work into the JMGov search project because I have hit a wall in terms of how deep I can drill down into the network of websits. I now need to go 4 levels deep (inception style, lol) and the code just cannot manage that amount of data. I will need to do a partial read of website, crash out and then be able to continue without losing track of where I am in the structure. Previously I could store and crawl the entire structure in memory but now 4 levels deep I have gone down a rabbit hole that I cant crawl out of without something clever to guide me. That clever thing is what I need to figure out.
This summer feels like its going to be a scorcher.
I need to restart playing Persona4 for the ps2. I was about 20hours into the game which I stopped playing in order to do something else. The game is time sink but it has great mechanics and cool story. I dusted the ps2 off but I have not connected it as yet because I have been distracted by 80s monster movies and westerns like HUMANOIDS FROM THE DEEP (1980) and Death Rides a Horse.
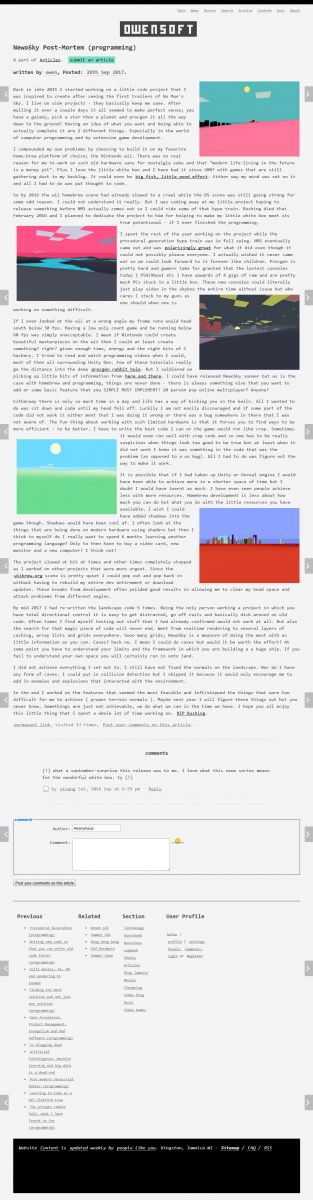
In April2018 I finished NewoFox a game I wrote in the C programming language on Wii hardware. Still tweaking it a little big but for the most part it is done at runs at 60fps. I wrote a postmortem on it as well.
I went to get my car aligned and apparently it needed a whole bunch of front end parts and shocks which had me doing alot of online search for parts since my car is a bit rare in these parts of the world. I am still going to need 4 tires because of the damage caused by the bad shocks.
In Jan2018 i finished the JMGov search project. The next phase of it will be to automate how it calculate that "JPS" == "Jamaica Public Service" with nothing but artificial Intelligence. This is going to be a challenge because my current database is 200mb and my computer is already at its limits.
I have a bunch of new tech articles in draft. I need to get them out before they burn up in the oven. I tend to go too deep in the metaphors, write too much or make nasty spelling errors so I am taking my time to fine tune all my articles before releasing them. Current drafts include "Technology, Tax Offices, Uber and Customer-Centricity", "Open Source, AI, Mind Control and Code Slaves" and "Ideas and bullshit circles". I am writing all these in parallel which kinda makes them take longer but it is a lot to cover and I have to actually use my brain to write them as opposed to simply clicking the retweet button. I have been slacking off on much of my writing but work/life has me a way.
I spent a weekend and did a mid year blog design refresh 2018v2 as seen in the attached photos. I am going back to a plain white background with big text almost like CNN. The text is 110% bigger than default and more roomy. Despite how simple it might seem the theme incorporates years of CSS knowledge and looks exactly the same in pretty much every browser in the history of the world.
I need to also start work on a new web analytics system for the blog to replace google analytics but I am not sure when I will jump on that grenade.
I also updated the algorithim for the news portal. Featured articles should be more varied and frequent now. You can also follow it on twitter @ twitter.com/softnewsmag because featured articles and categories are automatically pushed to the twitter feed using the dlvr.it service (free account, that is limited to 10 posts a day). It also has 500 followers on facebag but I am not sure that counts for anything. I need to get the twitter base up since its just at 60.
I think that is almost everything I have worked on in the past 6 months and will probably run me to the end of the year unless I side tracked by something more interesting.
I think I have squashed all the bugs now. 90% of the page font is default size which is masterful. 10 years ago I would never have thought it could be done.
Change log;
Fixed a longstanding bug in pagecache that so that any user can rebuild the cache once they make a change. Instead of just admin users.
Redid the profile edit page with new autoform
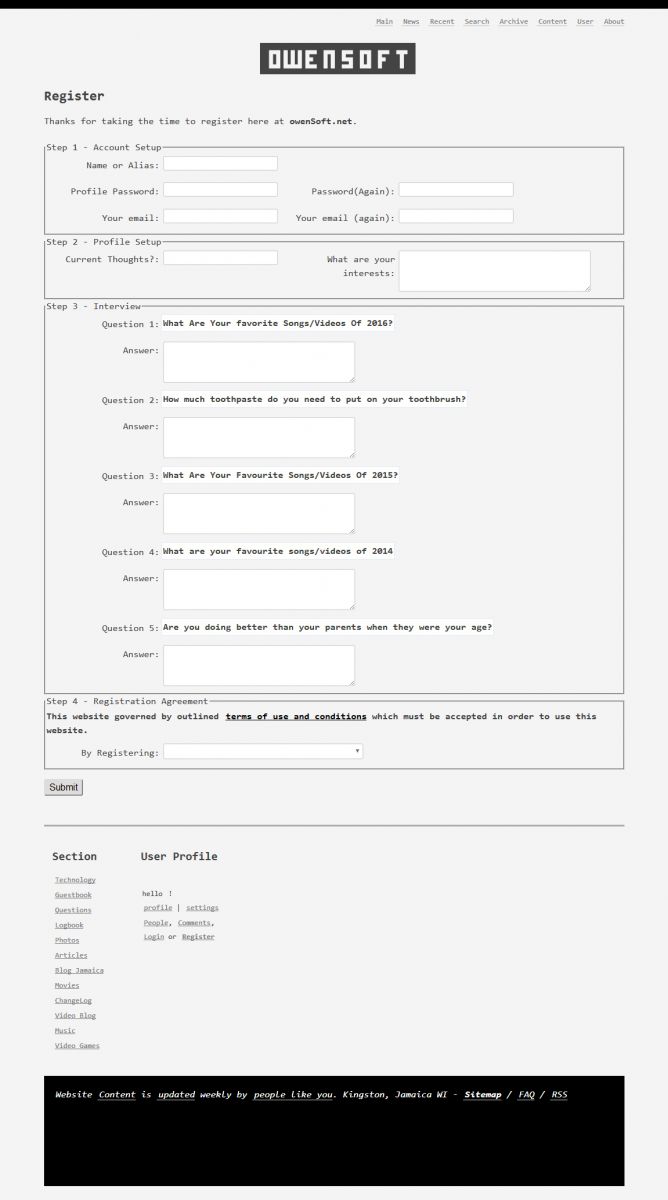
Fixed layout problems with registration screen
Messed around with how user profile pics are stored.
Reduced number of questions asked during registration interview to 5
Fixed the pg gallery so that the older small images do not get stretched to fill the screen space
When editing posts/items the photo grid shows up as expected (long standing bug) in both views
Kinda late down in the year for a redesign but the old design was over 2 years old and I figured that I would get a early start since I have both the motivation and the time (which is a rare occurrence in life).
This time around I am going for simply, clean grays inspired by xxiivv and v-os.ca. No new mastheads as yet but might add some in the future if I feel up to it.
I fixed some bugs here and there as well. Registered users can switch back to the old theme if they so desire.
The thing about software is that you never truly finish writing it and it is never in a state of "perfection" except for that moment right after you write a new line of code and no errors pop up. Right after that it starts going downhill as you discover more edge cases and faults.
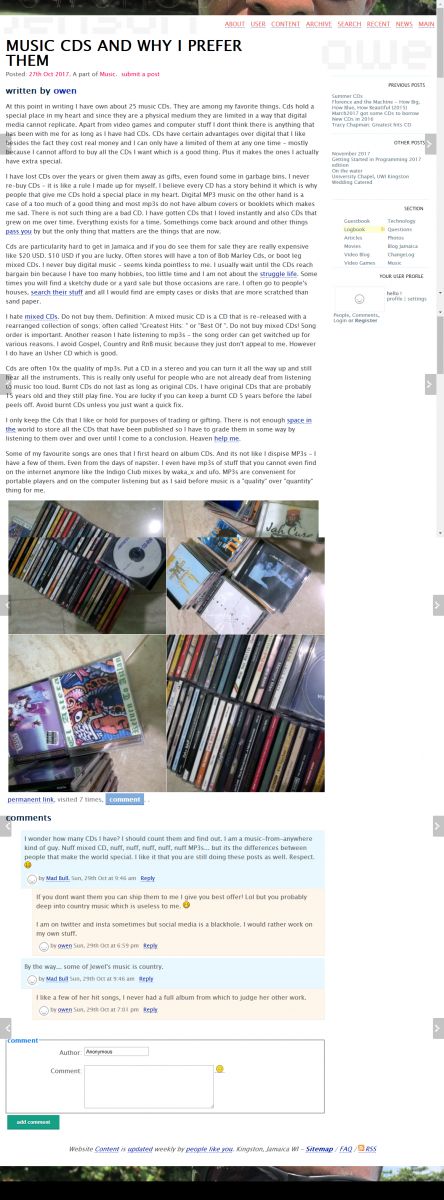
I am going to go for a simpler setup now, probably fix some long time annoyances alot the way. Vue.js? Attached are screenshots of the blog as at Oct2017 using a browser plugin called "full page screen capture".
I have never been big on design or bueaty but I have grown to like whitespace over time. As far as the code goes it is very simple. I think I will skip css modules this time around. *I notice that the screenshots don't come out well might been time to increase the max resolution on my images.
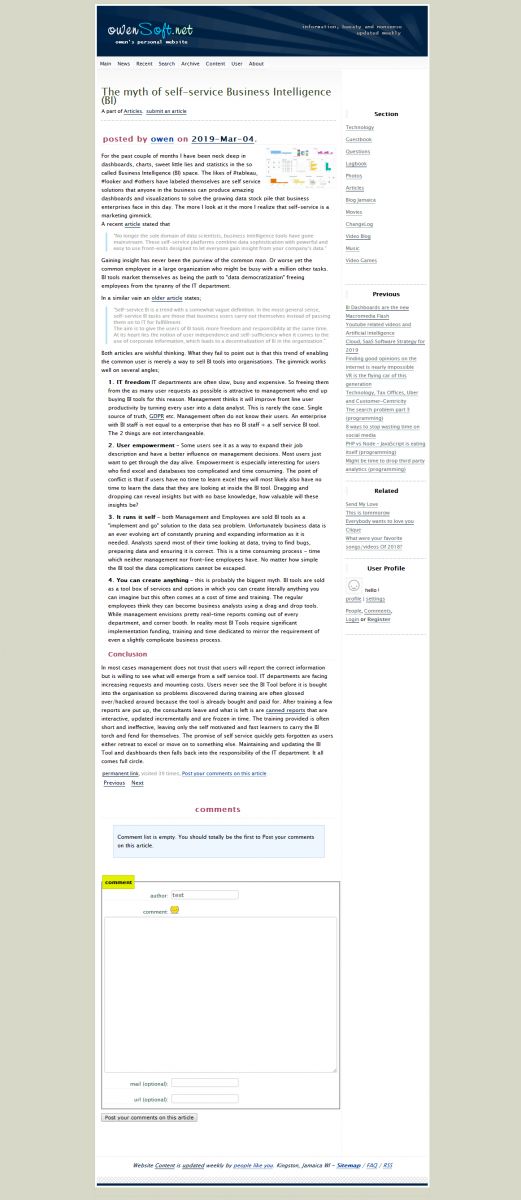
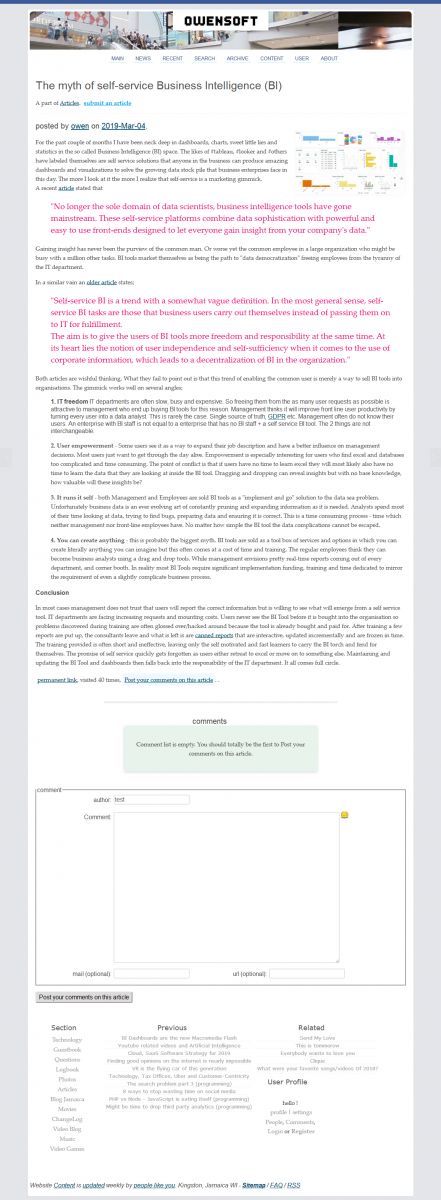
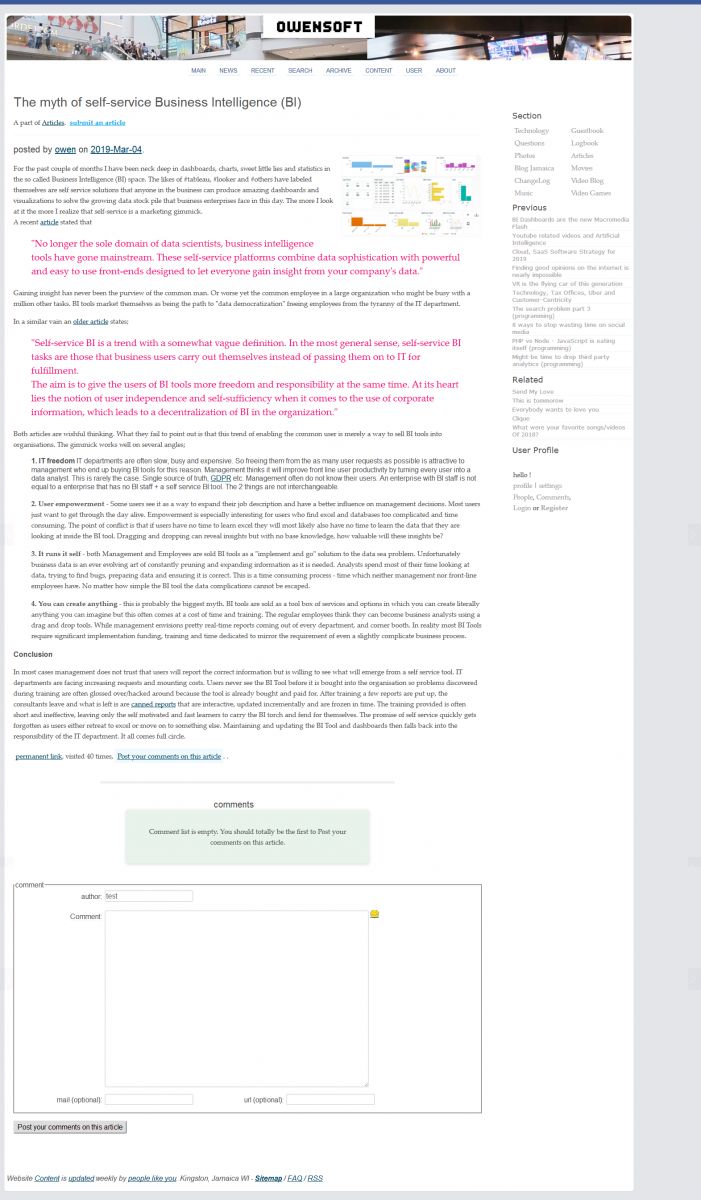
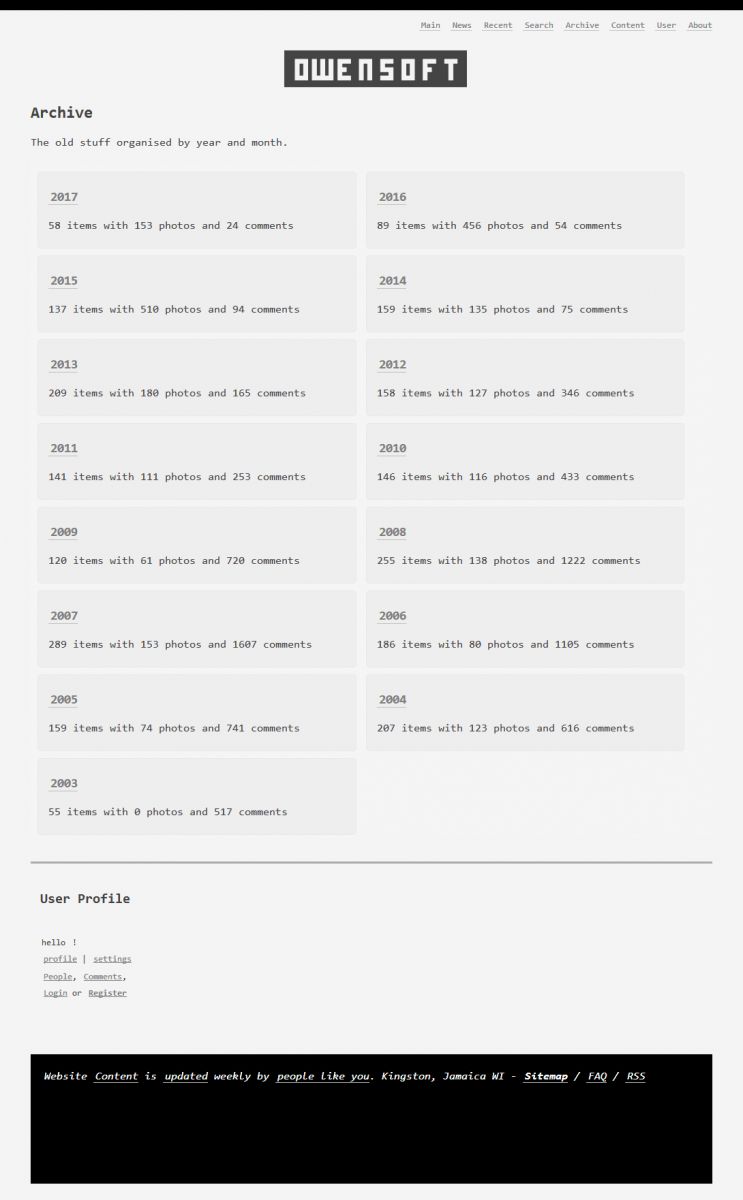
![blog [url]/v4/about/[caption]about[/url] page screenshot](/v4/photo/main/2698.jpg)
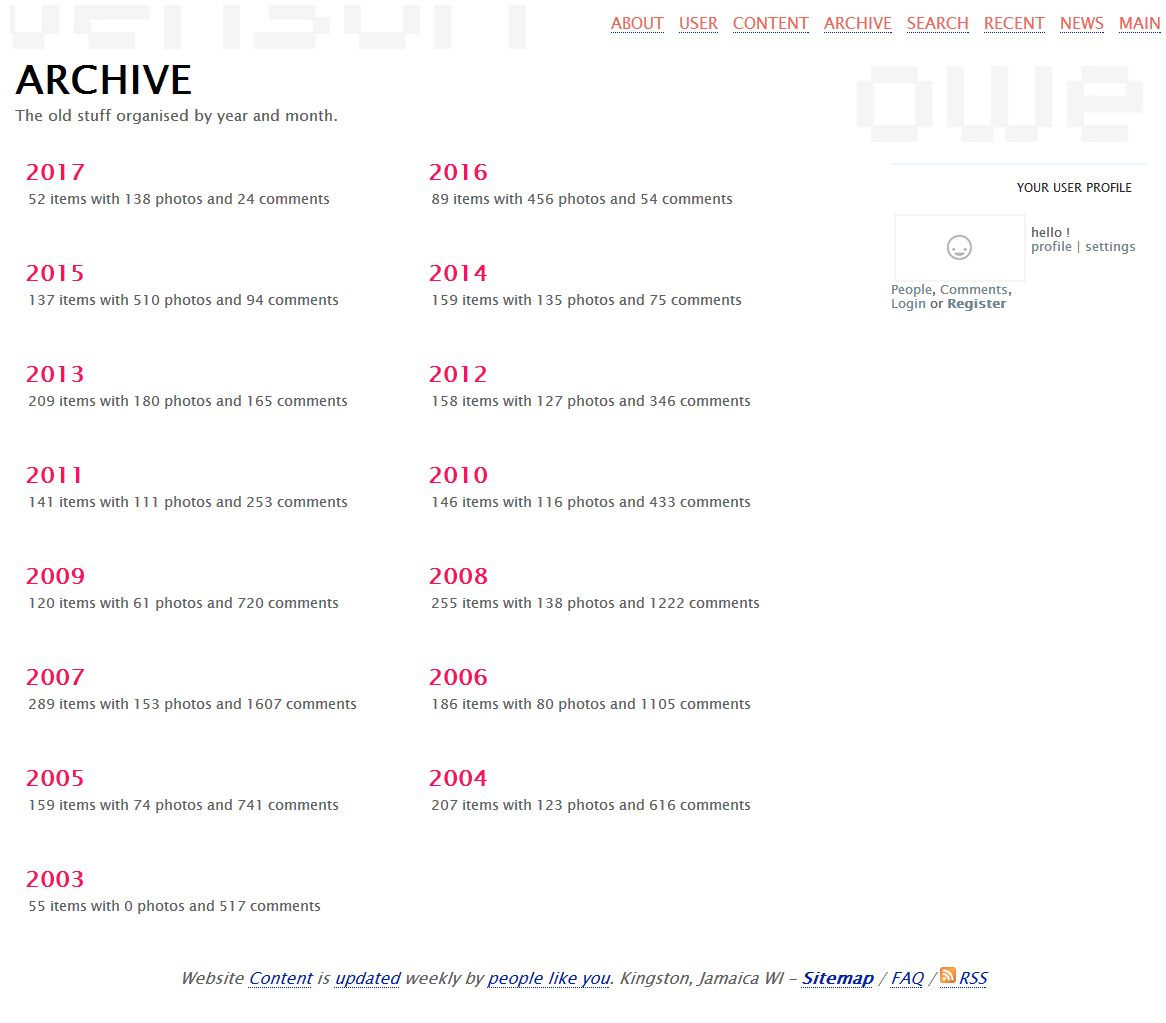
![blog [url]/v4/archive/[caption]archive[/url] screenshot](/v4/photo/main/2699.jpg)
![[url]/project/jmgovsearch/[caption]jmgov[/url] screenshot](/v4/photo/main/2700.jpg)
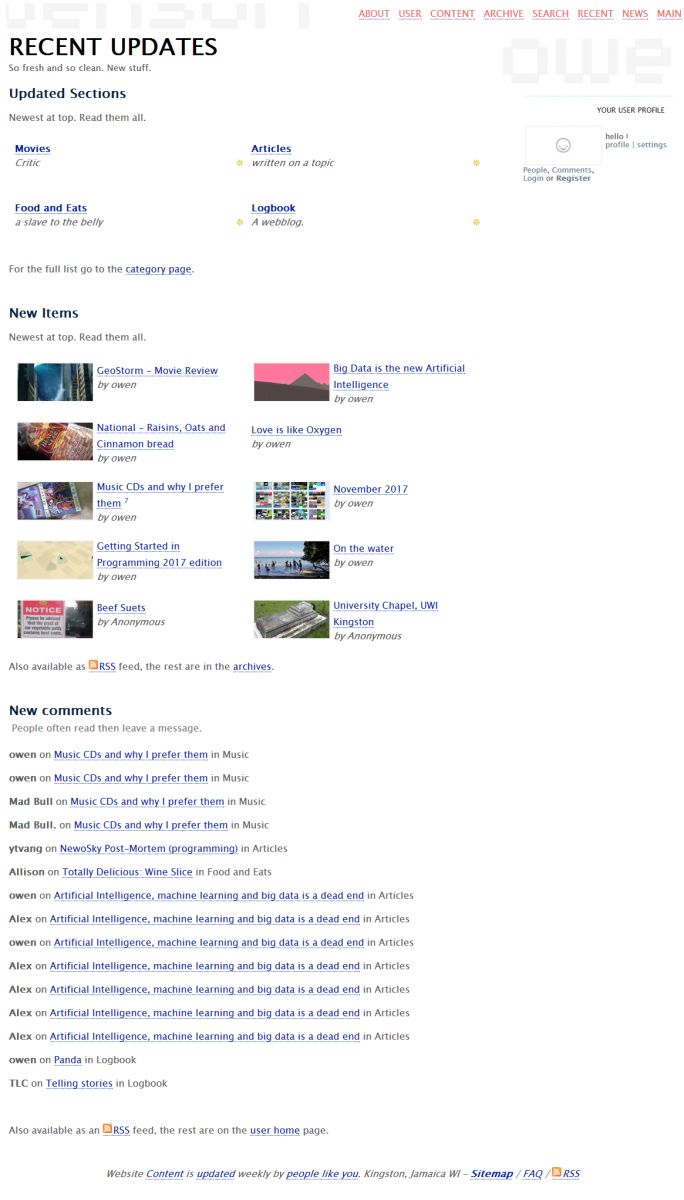
![News [url]/news/[caption]aggregator[/url] screenshot](/v4/photo/main/2701.jpg)