The search problem part 3 (programming)
Page is part of Articles in which you can submit an article
written by owen on 2018-Jul-06.
This is a continuation of a series I am doing my JMGov Search project. You can read the previous; Part 1 Part 2.
So I had a little free time and re-wrote the web crawler/spider. A separate program that collects the web links you see in the search results. The crawler had to be re-written because the code was messing and I was seeing some inconsistencies. Also I saw mention of gov website called JCPD on television that I could not find in my search tool. It was definitely time to re-crawl the websites to see if I could pick up this missing website but gov.jm did not seem to be updated - probably never will - so my only option would be to increase my crawl dept from 2 levels deep to three. Currently the search dictionary is 4000 links and the increase caused the dictionary to grow to 28000 links. The offline cache was 200 mb of html web pages now inching towards 1 gig. It was a surprising increase but I wanted the application to be as complete as possible.
Of course my old home computer could not process all that data in the 160 seconds alloted and finding a faster computer is not a productive way to solve problems. The new strategy is to crawl, parse and cache each page individually, allowing a chance to continue after I run out of CPU time. The web crawler had to be re-written to continue from where it last crashed. When it crashed a simple meta-redirect re-started the whole process and continue where it found a missing file. It took all afternoon to grab the new links roughly 24k and at the same time I had to be watching the crawler to see if it started picking any large files and promptly put in new exclude filters.
By the time the crawler was done windows explorer could barely keep up, the cache folder had 40,000 files and was 986 mb large. The cache folder is a flat file structure (for now) with each url having 2 files; one file is the actually html of the page and the second file contains the url to the page (It should be obvious why it is done this way). Both file names are md5 hased using the url so that I can grab them quickly at random without additional logic. Dont even mention putting all this crap in a database - sometimes over engineering wastes valuable time. The biggest regular HTML page is about 986kb excluding files which look like HTML pages but are really PDFs, those I blocked at the URL level because I cannot manage the extra data. And I am not going to the business of parsing PDFs. Sometimes I end up ignoring entire domains like .nz or .co.uk just to prevent the crawler from going too far off the reservation.
Each url that it visits, it takes all the links that are on the page but I realized only after the fact that some pages have way too many external links. It is not so bad when it is a "contact us" or "about us" page but some government websites are really over designed with static information, PDFs and crap. The extra noise of the new links is certainly going to cause trouble for figuring out the best search results.
After some tweaks and filters to remove some annoying websites like RJR. The only reason I kept the terrible JIS wordpress website is on the slim chance they might send the bot to good pages. The new crawler ran for 1.25 hours and returned 21505 links into a secondary cache. All of this is only possible because I am running on a primary cache of 1 gig that I have amassed. I am not sure how long it would take to do a 100% refresh but I am estimating it would take a 4 or more days of downloading on my current connection i.e. if the crawler doesnt get blocked before it finishes. I have to applaud the government website that actually stick to basic web conventions because the trash out there is deep and wide.
Another issue that popped up is the naming of the link: each link has 2 titles, the text that is in the A tag and the text that is in the TITLE destination page. Some links are annoyingly created with "click here to view info" and others link to pages with generic titles like "Embassy of Jamaica - Tokyo". Worse case scenario is that both options are bad and I just go with the alink caption. If both are short enough but not exactly the same then I add them together with a + sign.
I was also contemplating switch to Vue.js or ReactJS but it did not seem like projects that used to take months and hundreds of lines of code could be achieved much faster with well-structured prebuilt patterns and functions. Especially since I am working on all new code.
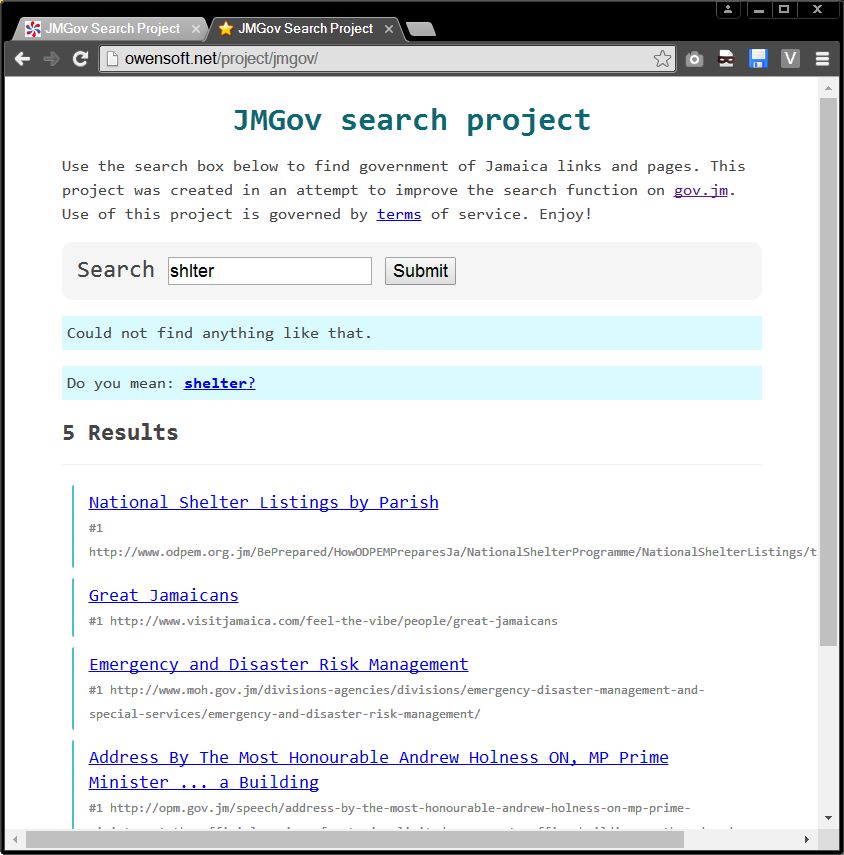
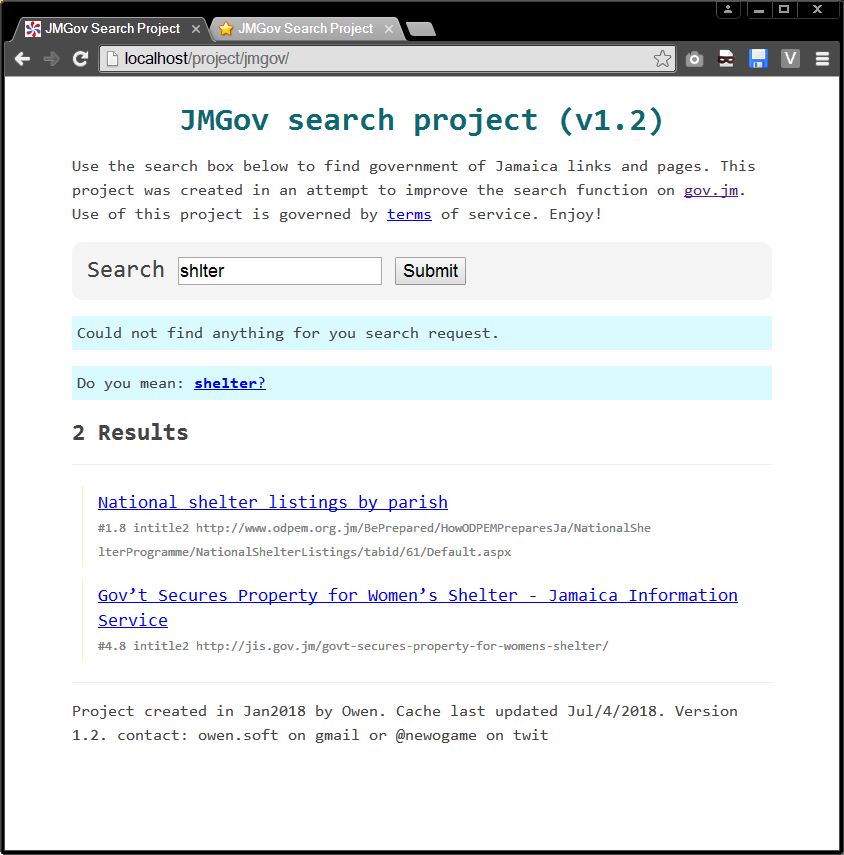
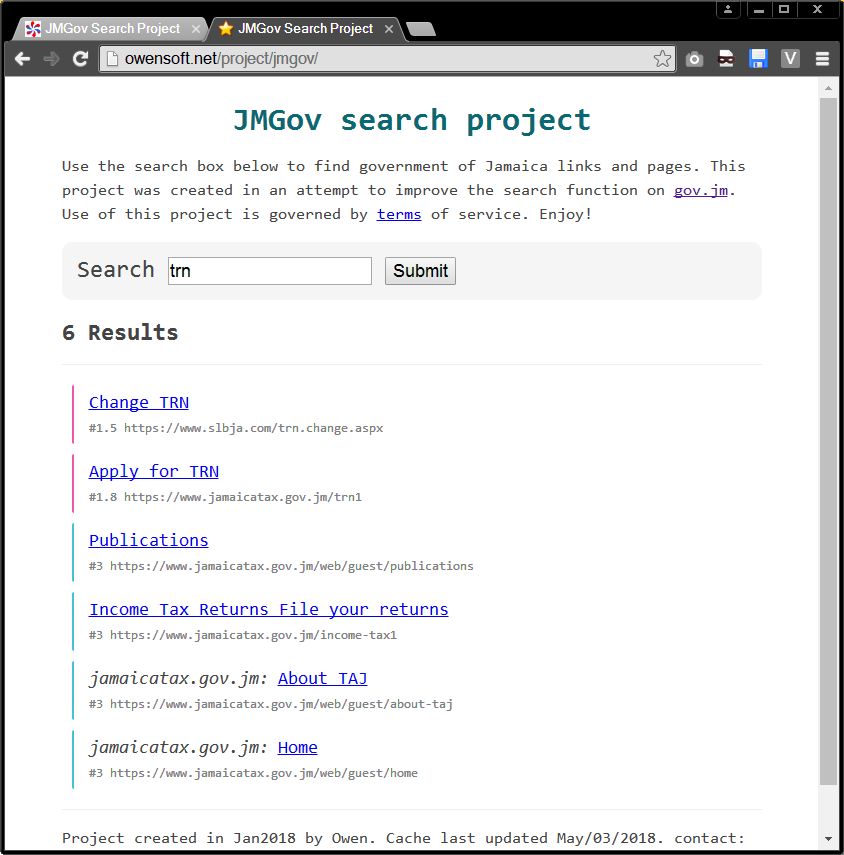
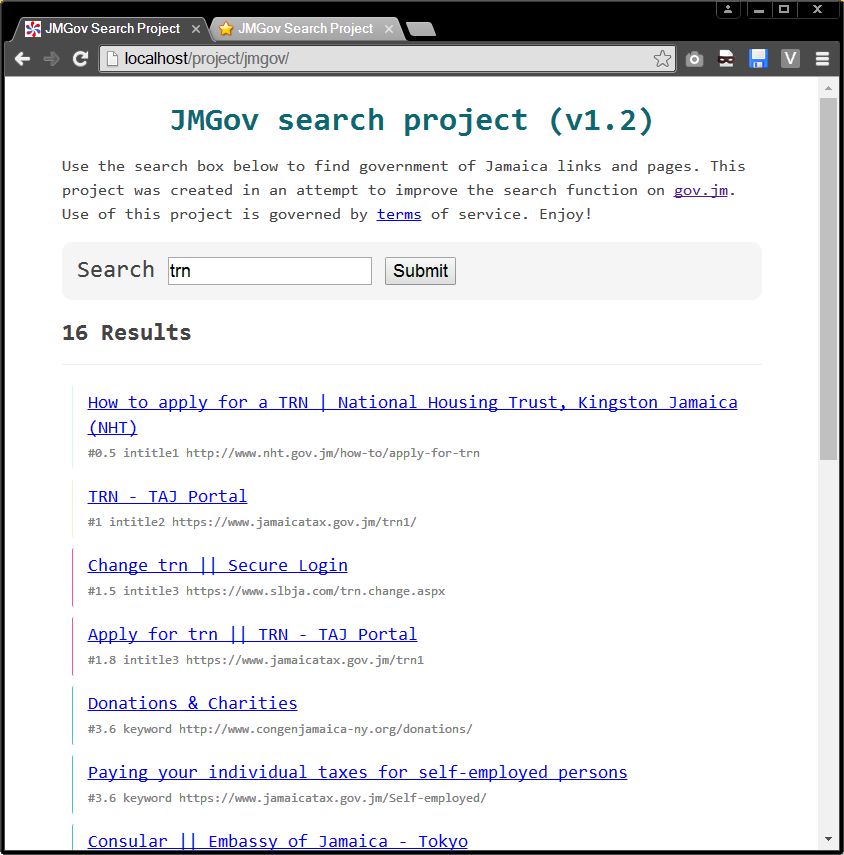
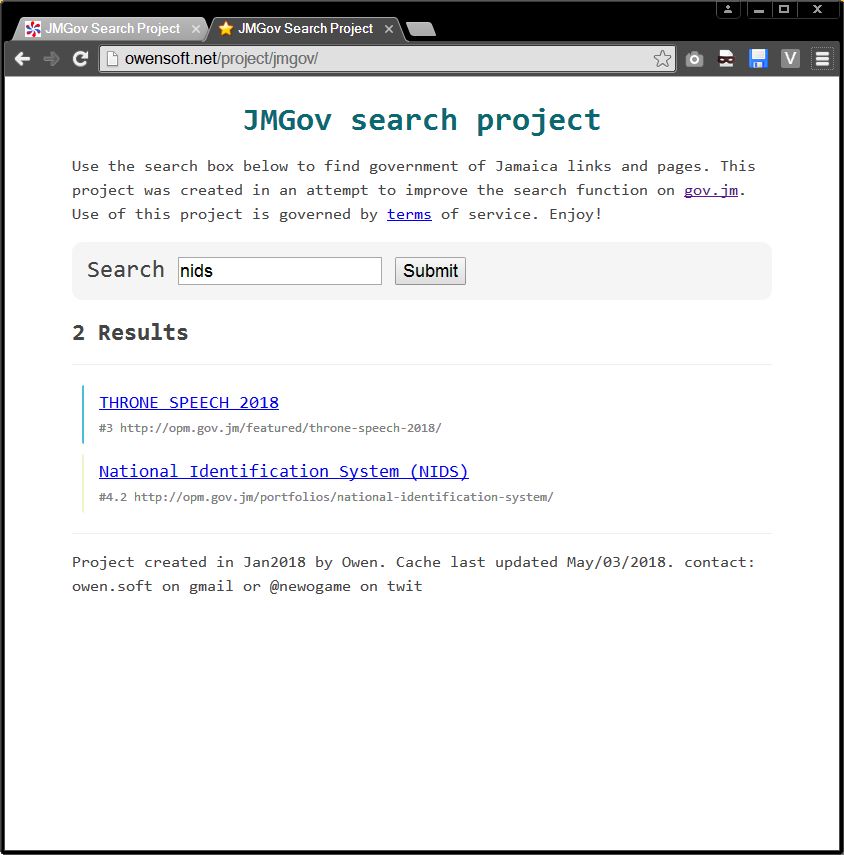
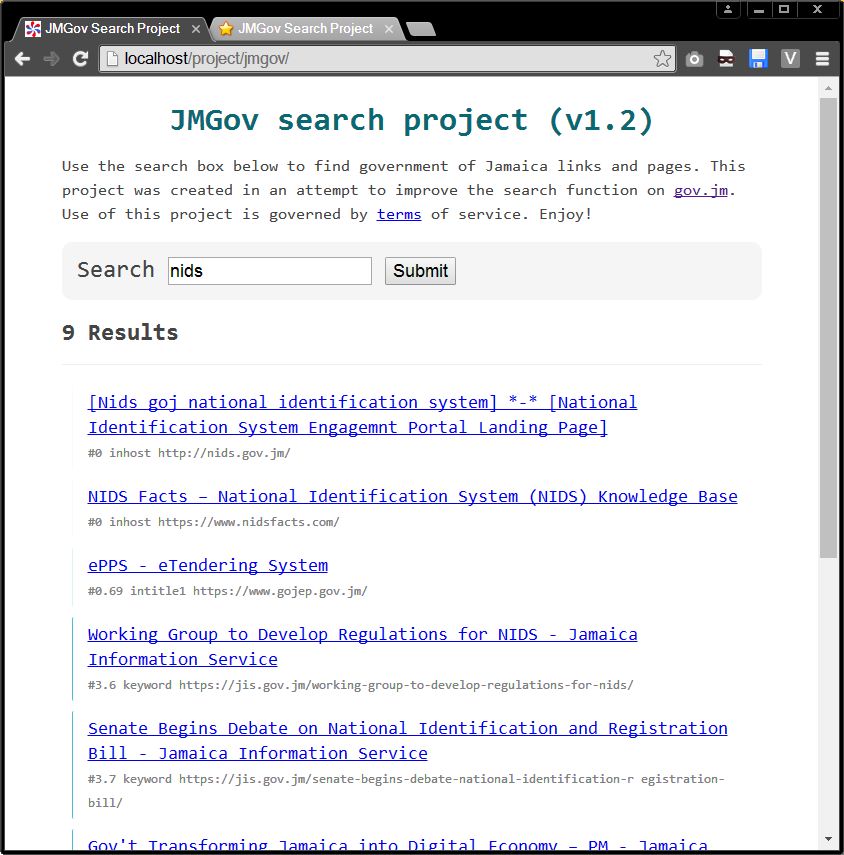
That combined with alot of little tweeks to the picking algorithm which you will probably be able to notice in the before and after screenshots attached to this post. Fixed some stuff, broke others. More links means more data to shift through but it should lead to more comprehensive results. The overall search should be better now and more smart. No reason to keep the old github versions online so I main see screenshots comparisons below or try out the latest version on the JMGov Search Project page. If you have any questions post a comment. I mostly test by searching for words like 'trn', 'tax', 'jamaica', 'visa', 'career', 'lost passport', 'tourism', 'andrew' etc.
Todo List
- I still have not figured out how to equate certain phrases with acronyms like TRN = Taxpayer Registration Number
- Also I need to find a way to way the importance of different words in a search query. Right now if you search for "1999 Honda Civic Blue" it assume all the words are equally important.
- Searching for vision2030 has alot of broken stuff.
- Use inbound and outbound link counts to calculate some kind a ranking of link importance.
- Switch to Vue.js or ReactJS on Node.
- Start a open source github.
- Index the final 10mb cache based on each word (currently 200+). This is going to make the cache explode in size with duplicate information but per search query in going to be faster.
- Load HTML meta descriptions
permanent link. Find similar posts in Articles.
comments
Good stuff!
by zagga 2018-Aug-17