written by owen on 2019-Jun-03.
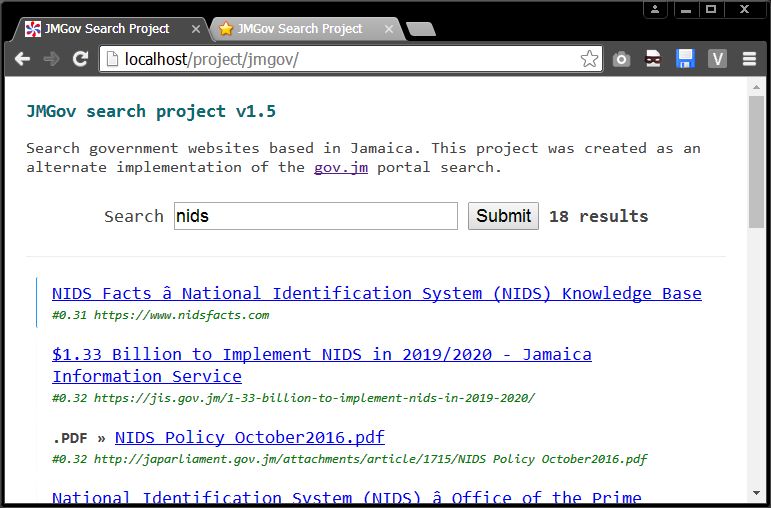
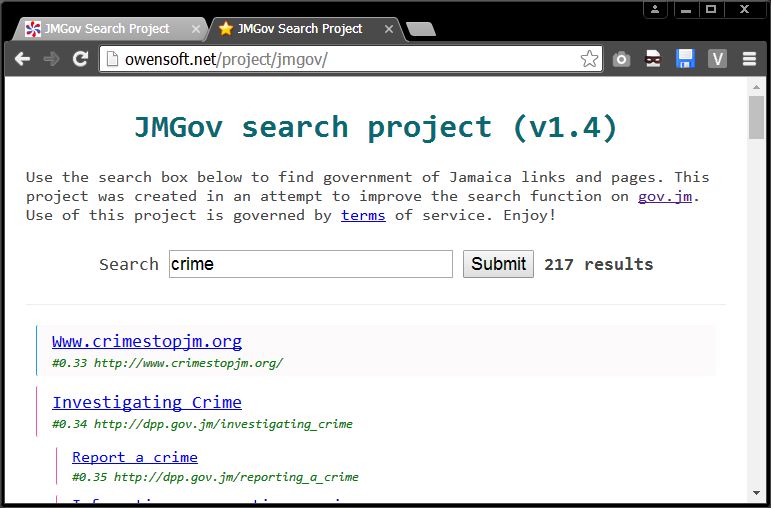
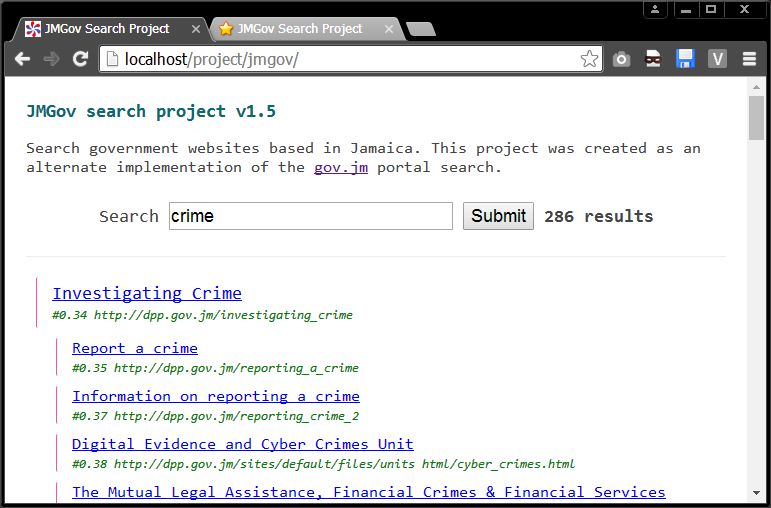
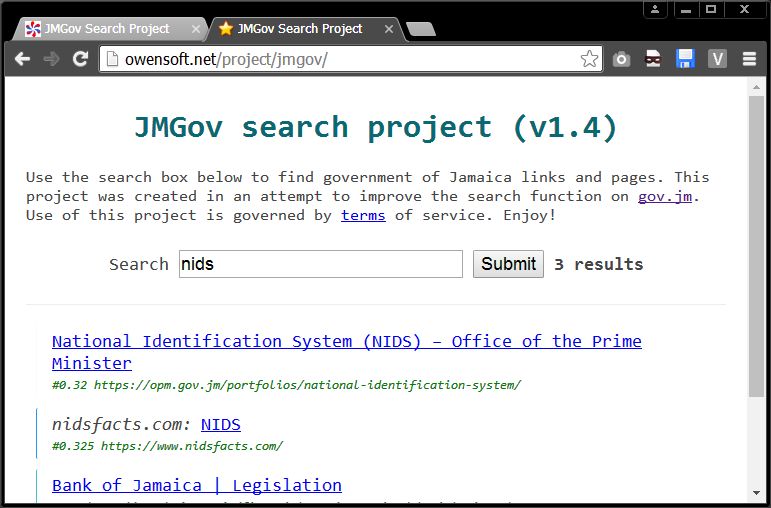
I had some time so I worked on the search project. Prepare for a highly technical rant;
So I upgraded my hard drive to a 525gb SSD (from a 320 gb, 7200 rpm) because I saw it being sold and I figured I could use the speed. Reads and writes increased by 150%. The SDD is SATA3 but my motherboard is SATA2. The increase is noticeable but not enough to do a full crawl but at least I can quickly open a directory with 30k or more fies. I also deleted the entire cache and started re-crawling all the old stuff - I figured this would be a good time to start over and see if I could get rid of unused files.
More Crawling
I am going 8 levels deep this time around. I am now using the path cache to reduce the amount of double crawling that happens when I check a link several times because most websites have a redundant menu on every page - often this menu has a million links point to the same places.
Roughly 22k unique links now. I added better detection of 404 links and someone seems to have installed Mod_security on my website which causes other problems which I had to work around.
My search cache went from 2gb to 6gb in the matter of a day - I figured my deep crawl must have been doing better. But then I checked out the cache and realised that I had stumbled across a new type of unecessarily HUGE HTML5 webpage; 2 websites had a chart engine which sent all the data to the client html - the biggest chart was 37mb - total was approx 4 gigs of chart data downloaded into my cache. The next culprit was visitjamaica who decided that they would embed a SVG image inside EVERY PAGE making each and every page at least 500kb - EVERY PAGE!
I need to put in a limit on how many links I will accept from one web page. Some pages have way too many links and repeat them constantly.
I have also discovered new ways in which some wordpress websites are spammed by using hidden divs full of spam links onto each page that only robots will see. Once I discover the page I have no choice but to block the entire website until I have a way of detecting this programmatically. If I have to time I might post a list of hacked websites so that they can be fixed.
Popup menus on a webpage add serious bulk. Especially if you have a country listing. It seems cool to the user but its better to just have a country page with a single list of country links rather than have the country list embeded into EVERY PAGE on the website. One website had 240+ country links in a hidden popup menu on EVERY PAGE - the site seems light on first look but under the hood its a monster. I will be forced to implement a limit on how many links I retrieve from an individual page but even if I set it to 100 the first set of links will always be menu items.
HTML5 trash
Links to large none-html files with no extension; example 1, example 2, example 3.
Current index 39918 links from the last re-index. Total cache is 3.91 gigs. Ignoring 167 unique phrases/websites. Crawling 8 levels deep. Sometimes I leave my computer running over night only to realise in the morning that there was a bug in the code that I have to fix and start the process out again. Most of this re-crawling is luckly local to my disc.
As I finalized my changes and watched my robot crawl I thought to myself that building a search engine is hard but not impossible. You really need a whole lotta storage and computers. Not a really fast computer but serveral computers working in parralell. 5000 computers is about right. You would need a computer for every letter of the alphabet, plus words and phrases. despite the large amount of terrible websites out there.
I eventually decided to remove visitjamaica from the index because it is a terrible terribly bloated website.
Discovered a bunch of ophaned and ignored links and got the list down to 27837. I am also trying to put descriptions under the links which requires figuring out which parts of the page are actually useful versus advertisements and menus.
Conclusion
Anyway search project version 1.5 should be up and running check it out and do some searches. Note that searches will take much longer now (2secs) because the index is now 31mb.
permanent link. Find similar posts in ChangeLog.
comments
Comment list is empty. You should totally be the first to Post a comment or feature request.