Diving into the search problem (programming)
Page is part of Articles in which you can submit an article
written by owen on 2018-Feb-26.
preamble
*below is a thought dump for a project I completed in January 2018. You can view the completed search engine working protoype here; JMGov search project. Reader discretion is advised.
Since the launch of the gov.jm portal I have been annoyed with this one particular issue that no one seems to want to tackle with these government websites; "search". There is a ton of content and software devs seem to have given up on the whole issue of making a really good search feature on these large websites. So I am going to try to do a little proof of concept side project to see if I can improve on the work that has already been done.
The issue
The website is full of random, Unique links with different titles that point to the same location. But gov websites on a whole love to upload scanned forms, pdfs, text documents scanned as images, word files, text hidden by CSS, and all manner of HTML sins.
Re-formatting all the PDF content to make them searchable would be a mammoth task for any group of people much less one person. Plus most of the content is either old or noise. I am not even going to try to figure out how to get at the text in these documents - it would be a waste of time and my limited storage space.
So what does one do? I have no choice but to work with what I have. I will have to crawl the entire websites and group all the links and information into relevant categories in a way which I can use to produce a simple search. I need to be quick on this project because I am a man of too many hobbies.
The secret sauce solution
Based on my prior knowledge of search engines, they seem to get better the more people that use them - storing all user actions until they have so much information that they can guess what you are going to type next. But I do not have access to that much search usage data so that is a no go. And based on the "popular" links currently shown on the website (since it launched) it does not not seem that they keep track of such information themselves. In which case I will have to be clever when determining what is considered popular/useful.
Getting Started
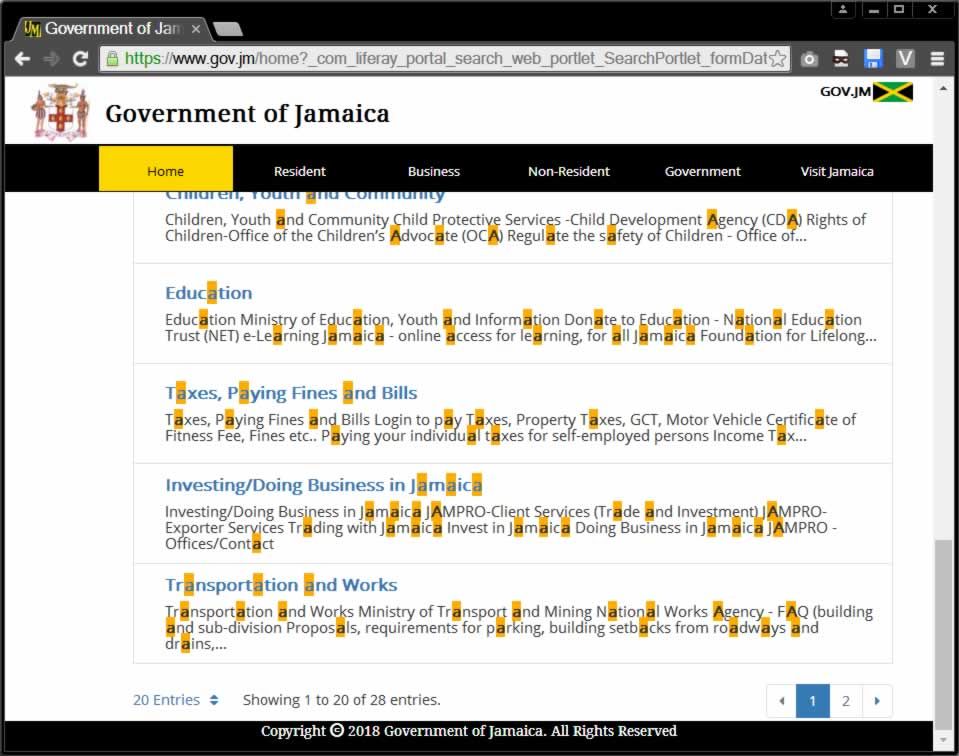
The first task will be to get all the links and the titles and build a dictionary. The website seems to be built on Liferay Portal CE (400mb Tomcat). I am not sure why they needed a CMS to build sub a simple website. You can expect a large percent of the content to become 404 by next week as the external websites change and update.
There could be some dynamic things going on in the back ground but it does not seem to be much for than FAQs organized into brochure. A brochure is good for browsing but not so much for searching. This FAQ page is a very funny play on words. I bet this website was built using Artificial Intelligence.
Tasks
Things I need to do;
- collect every link and title that is on the home page
- catalog the links by type; internal, external, files
- take screenshots
- browse the internal links and repeat step 1
- browse the external links and collect the data
- avoid triggering any kind of DDoS alert
- make a data structure that can determine relevance without having to manually arrange all the information
By the looks of it the majority of the links are external which is going to make my task even more difficult considering that I am working with potentially 250 different ministries with different websites, designed by designers who like to use stock photography just for the kicks. I might be biting off more than I can chew but as they say; "nothing tried, nothing done".
Determining Relevancy
The structure of the website does help a little but there is a disconnect between what the users are looking for versus what the design wants show. This is another hurdle to cross which is going to need lots of work on my part.
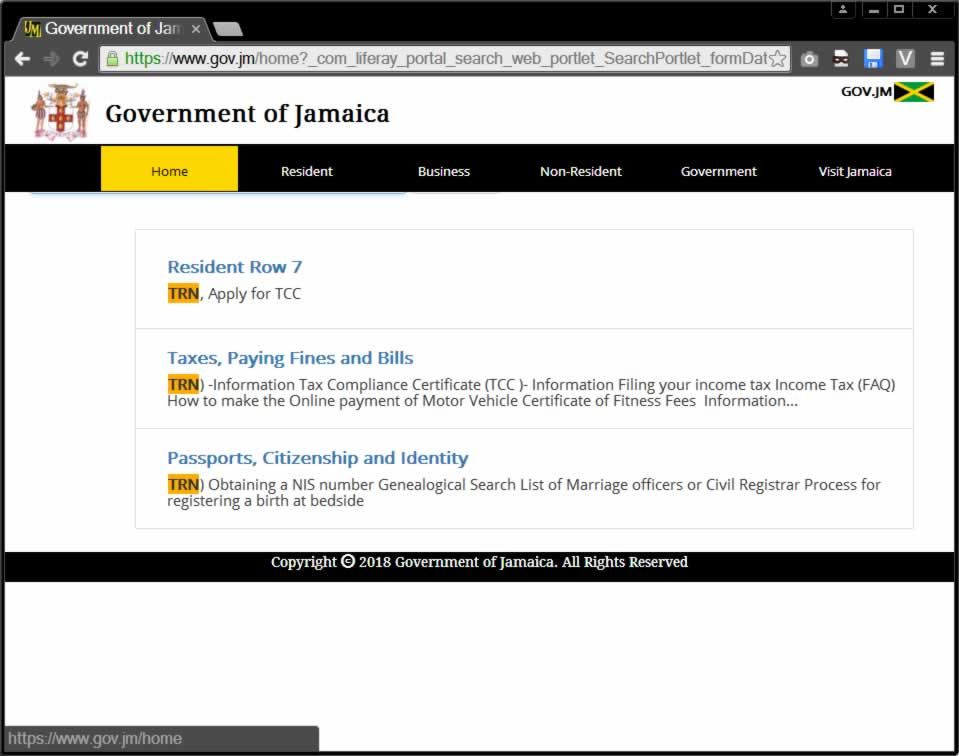
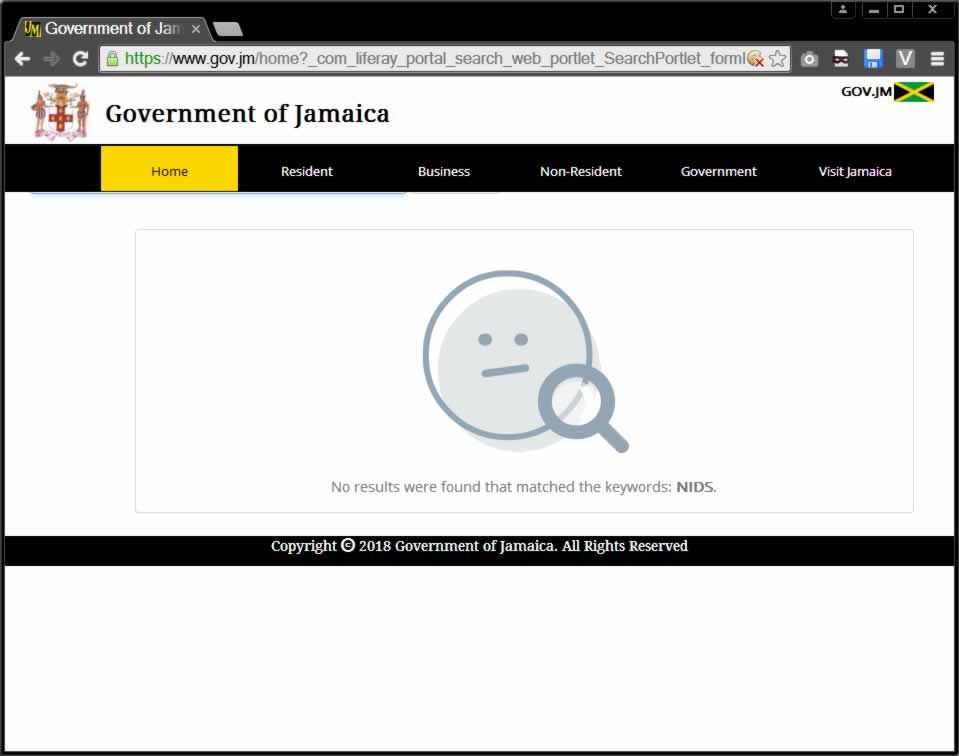
I can only guess what a particular user wants based on my own experience and the results that I can currently see. If I search for "passport" I get 2 links. The first is a link to Passports, Citizenship and Identity and the second to Government Forms and Online Services. Both these links send the user to the same page. This does not really help much since those links are exactly the same as the ones in the header menu. I want to provide more information to the searcher. And at the same time not flood them with information and not send them on a wild goose chase down a big list. How do I do this?
The 404 problem
As with any significantly large portal website you are going to come across the problem of pages simply disappearing either because someone changed a wordpress theme or a whole department decided to change all their links. Sometimes you stubble across bad links that somebody just forgot to fix. Then you have the people who mislabel links with text like "Learn More" or "Click Here for more info". A perfect example is this page which is fancy but pointless. Pretty URI directories that have no parent. Sometimes with the change of government entire ministry websites get nuked, renamed and redesigned with no archiving policy and thousands of dead links. I could go on and on. But such is the nature of the web.
Search tricks
I am not going to hand pick the results or try to map them to certain words to make them look good. And I am not going to waste my limited resources by setting up a database or pay for a cloud service. I am going to have to go old school on this project. Here is how I plan to set up the search logic;
- - Exact word search - whatever the user enters I check to see if exactly that exists
- - 70% word search - if you enter a bunch of words then I will see if anything contains at least 70% of those words.
- - infer a parent based on unique results - certain results often have a common parent website which is more important than the individual result.
- - infer based on commonality - infer a result based something that is common between the other links in the set of current results.
- - order of keywords; assume the first thing you enter is the most important and the words that come after are supplementary
Conclusion
At the end of this little project I realized a few things about the Internet mostly that there is a ton of redundant data and that it is virtually a bottomless pit of content. If I go even one level deeper I could potentially double the size of my search database. It is no surprise why few people even attempt such a project.
*footnote uses one or more of the following tech; Cloud AI, Java, C, Vue.js, Blockchain and PHP. 10 days of development time and 2 days web crawling. The cache contains 3628 entries, 23095 words, 4.5mb in size. Code: 562 lines in UI, 587 in crawler and 39 lines in CSS. You can visit and test the project on its project page.
permanent link. Find similar posts in Articles.
comments
Comment list is empty. You should totally be the first to Post your comments on this article.